
Anthropic dropped Claude Opus 4.7 today, and the reactions from early testers are not subtle. One company says it autonomously built a full Rust text-to-speech engine from scratch. Another saw its visual accuracy jump from 54.5% to 98.5% versus the previous model.
This is not an incremental release. It is a real upgrade for anyone whose work touches code, documents, slides, or data.
[IMAGE: Claude Opus 4.7 launch banner or hero image from the Anthropic announcement | Source: Anthropic.com/news/claude-opus-4-7]
What Actually Changed
Opus 4.7 replaces Opus 4.6 as Anthropic's flagship model. Pricing stays identical at $5 per million input tokens and $25 per million output tokens. No premium for the upgrade.
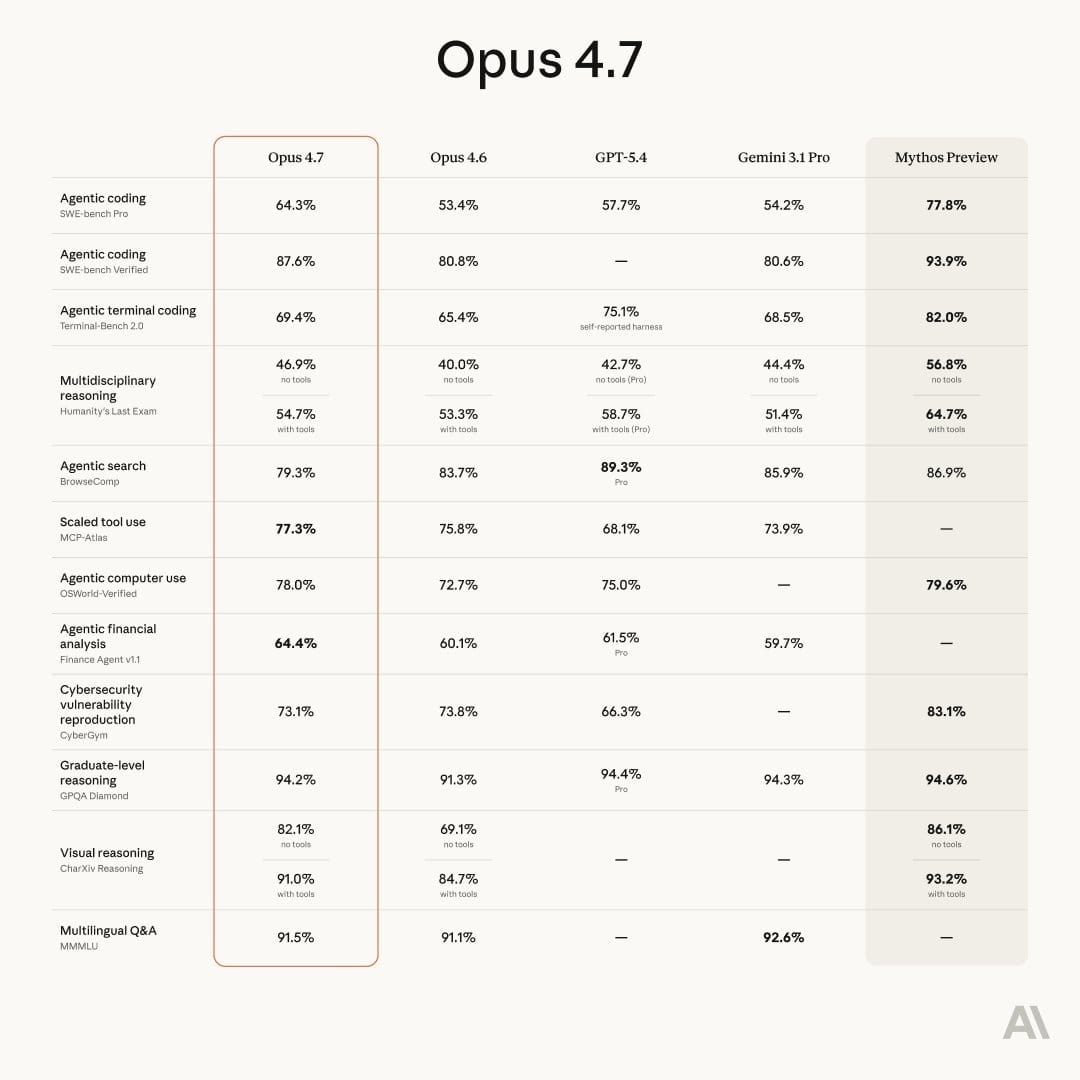
The headline improvement is software engineering. On Cursor's internal benchmark (CursorBench), Opus 4.7 cleared 70% versus 58% for Opus 4.6. Replit reports the same quality at lower cost. Warp says it passed Terminal Bench tasks that every prior Claude model had failed. Rakuten saw 3x more production tasks resolved on its internal benchmark.
The second big change is vision. Opus 4.7 now accepts images up to 2,576 pixels on the long edge, roughly 3.75 megapixels. That is more than three times the resolution of any previous Claude model. XBOW, an autonomous penetration testing company, saw its visual accuracy jump from 54.5% on Opus 4.6 to 98.5% on Opus 4.7. For anyone working with dense screenshots, complex diagrams, or technical charts, this is the single most practical upgrade in the release.
The third shift is instruction-following. Opus 4.7 takes instructions more literally. Anthropic is explicit that prompts tuned for earlier Claude models may now produce different results. Users will need to re-tune.
Why This Matters for Your Work
If you use Claude for anything beyond quick chats, this affects you.
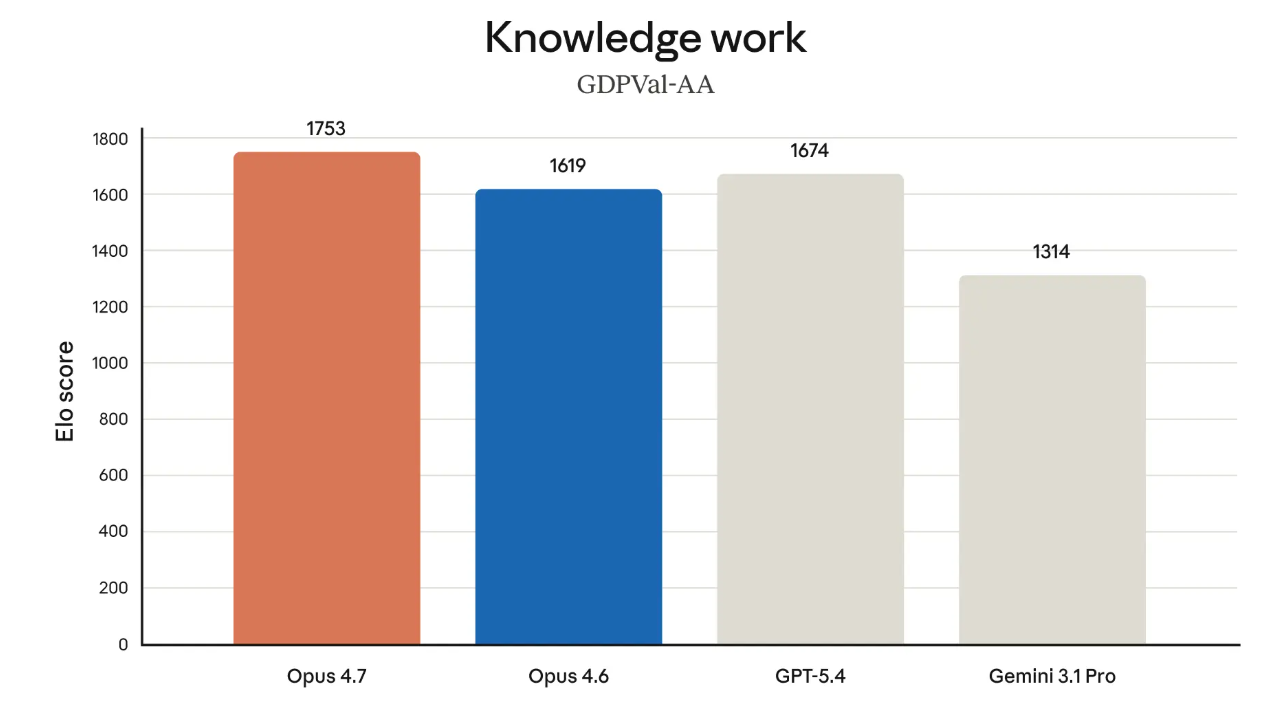
For knowledge workers doing financial or legal analysis: Opus 4.7 hits state-of-the-art on Finance Agent and GDPval-AA, a third-party benchmark for economically valuable knowledge work across finance, legal, and other domains. Harvey, the legal AI platform, scored 90.9% on BigLaw Bench at high effort. Databricks saw 21% fewer errors on document reasoning when working with source material.
For anyone building or reviewing documents: Anthropic explicitly calls Opus 4.7 "more tasteful and creative" at producing interfaces, slides, and docs. Hex, the data tool, says low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6. You get more for less.
For developers and technical teams: CodeRabbit reports recall improved by over 10% on code reviews, surfacing bugs that previous models missed. Notion saw a 14% jump on complex multi-step workflows at fewer tokens and one-third of the tool errors. Opus 4.7 also passes what Notion calls "implicit-need tests," keeping execution going through tool failures that used to stop Opus cold.
The model is also better at memory across long sessions. It remembers important notes across multi-session work and uses them to start new tasks with less upfront context. For professionals running long projects, that means less time re-explaining what the AI should already know.

What Else Ships Today
Opus 4.7 arrives with three additional updates worth knowing.
New "xhigh" effort level. Claude now has a setting between "high" and "max" that gives finer control over how hard the model thinks. In Claude Code, Anthropic raised the default to xhigh for all plans.
Task budgets in public beta. Developers on the API can now guide how Claude spends tokens across longer runs, letting it prioritize what matters on multi-step tasks.
New /ultrareview command in Claude Code. A dedicated code review session that flags bugs and design issues a careful reviewer would catch. Pro and Max users get three free ultrareviews to try it out. Auto mode, which lets Claude make permissioned decisions on your behalf during long runs, is now extended to Max users.
The Bigger Picture
Opus 4.7 is not Anthropic's most capable model. That distinction still belongs to Claude Mythos Preview, which Anthropic revealed on April 7 as its most powerful system ever, and also the first it has explicitly refused to release broadly because of cybersecurity risks.
Opus 4.7 is the first public model to ship with cyber safeguards designed as a testing ground for eventual Mythos-class release. Anthropic says cyber capabilities in Opus 4.7 were deliberately reduced during training. Security professionals who need those capabilities for legitimate work like vulnerability research or penetration testing can apply to Anthropic's new Cyber Verification Program.
This is a meaningful signal. Anthropic is releasing frontier capability on a two-track system: commercial Opus models for everyone, and Mythos-class models held back until safeguards catch up. Users get steady improvements every two weeks or so, while the most dangerous capabilities stay gated.
Two operational notes for anyone migrating. The new tokenizer can increase token usage by 1.0 to 1.35x depending on content. And at higher effort levels, Opus 4.7 thinks more than Opus 4.6, producing more output tokens. Anthropic says the net effect is favorable, but measure it on real workloads before committing.
Opus 4.7 is available today on Claude products, the API, Amazon Bedrock, Google Cloud's Vertex AI, and Microsoft Foundry. Developers use the model ID claude-opus-4-7. For most professional users, the right move this week is simple: upgrade, re-tune your most-used prompts, and let the higher-resolution vision handle the screenshots and diagrams that Opus 4.6 used to fumble.